Building an F1 prediction engine – Predictive Modelling Part II
This post will describe and explain maybe the most critical part of predictive modelling: how to correctly estimate the performance of a machine learning model. This is performed by setting up a trusted cross-validation framework. It’s crucial to get this right, otherwise your model performance estimates will not reflect the true model performance.
As always, here’s where we are in the ML pipeline:
- Data Acquisition
- Feature Engineering
- Predictive Modelling
- Evaluation Metric Selection
- Cross-Validation Set-up
- Algorithmic Approach
- ML Algorithm Selection – Hyper-parameter Tuning
- Model Deployment
But what is cross-validation? Long story short, cross-validation (CV) means using part of your training data (i.e. the one you know the true target) as a proxy for estimating the model’s performance on unseen data.
The most common form of cross-validation is the so-called K-fold cross-validation. K is a number you have to specify and is usually between 3 and 10. In the case that K is equal to 3, the procedure is called 3-fold cross-validation. The idea is to break up your training set into 3 parts (or folds). Then, you use the first two folds to train a model, you use the trained model to get predictions for the 3rd fold and you calculate the evaluation metric (e.g. RMSE) using the known target values of that 3rd fold. You repeat the procedure using the 1st and 3rd folds to train the model and the 2nd fold to calculate the evaluation metric. Finally, you repeat the procedure using the 1st fold as the validation set. The procedure is better explained in the chart below:
This way, you end up having 3 estimates of the evaluation metric. Based on these, you can calculate their average and consider this as the final model’s performance estimate. You may also calculate their standard deviation to get a sense of how sensitive your model is to different training data; the smaller, the better. You may also calculate the evaluation metric on each fold’s training data as well (i.e. the ones the model was trained on). By comparing this figure to the one calculated on the validation folds, you can diagnose if your model is underfitting/overfitting and then adjust the ML pipeline accordingly (e.g. remove/add features, add/reduce regularization etc.).
The most important thing is that the training and the test folds should never ‘see’ each other. For instance, if you need to normalize a feature, you should calculate its mean and standard deviation from the training dataset within each fold. You should not use the global mean of that feature since this means looking at the test fold as well. This will result in overly-optimistic CV scores and should be avoided in real-life (e.g. not Kaggle) projects.
Moreover, your training set should never contain information that will not be available when the model get’s deployed. Talking about predicting F1 race results, the training data for predicting a historical GP’s result should not include information on whether a driver eventually won that year’s championship or not. This information would tell the model to increase the driver’s chances of winning that specific GP and it is a piece of information that would not be available when predicting a future GP without knowing who will win this year’s title.
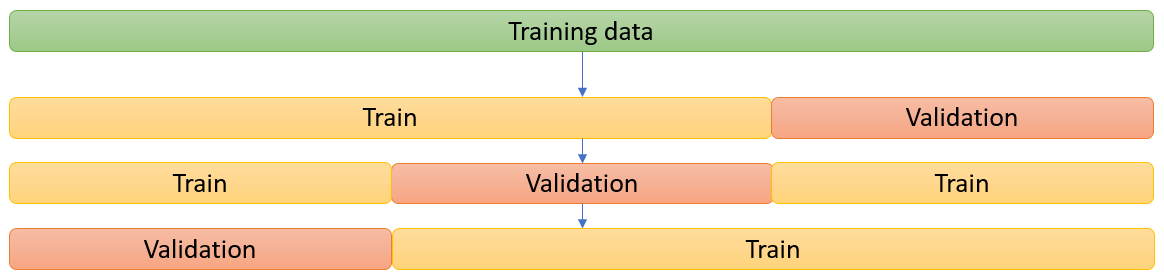
Given this point above, how should we apply cross-validation to data that are time-ordered (like F1 results)? The basic idea remains the same but instead of splitting the training data into 3 random folds, we break it in a way that the validation data always refer to a later period compared to the training data. It’s a bit trickier to set-up but it’s absolutely essential. Here is the schematic representation:

But how do we use these CV frameworks? It’s simple… We, somehow, select some features, an ML model and some specific hyper-parameters and run the CV pipeline. We end up having a score that shows the performance of the selected components. Then, we modify these components (e.g. we change the model hyper-parameters) and we run the CV procedure again. We compare the scores obtained and we can see if the change improved the results or not. We repeat this procedure until we are happy with the end-result or till we can no longer make any further improvements. Which hyper-parameters we select to run each time is a topic of its own, and I’ll share more about that on a later post.
There more ways to estimate the performance of a model but the above ones are the most commonly used. Cross-validation is a technique that not only allows estimating a model’s performance, but also enables comparing between different models or selecting the optimal model parameters. It can also be used for model ensembling by producing CV predictions, i.e. model predictions for the data that we already now the target variable. Furthermore, it can help diagnose whether a model suffers from under-fitting or over-fitting, whether more data would be helpful, whether we have too many features or we should increase/decrease the regularization. In total, it is a central part of the model building process and all practitioners should understand all details involved in the process.
Happy to answer any questions or ideas you may have!
4 thoughts on “Building an F1 prediction engine – Predictive Modelling Part II”
Very interesting!
But I still not understood everything, sorry. Let’s say we already have a dataset with races results for last x (let’s say 3) years and some features, how can I provide cross validation?
Hi Bogdan. Let’s assume you have 3 years data which are about 60 races. Also assume you want to do a 4-fold CV.
You should choose the minimum number of races to train a model, say 20. So, the 1st year will only be used for training, not for validation. Since you have 4 folds, each fold will contain 10 races out of the last 2 years.
Here’s how your CV would work: you train the model on the first 20 races and you make predictions for the next 10 ones. You calculate the relevant metrics. Then, you train the model on the first 30 races (or the races 11-30, this is a choice you have to take) and predict on the next 10. You keep doing this for the next 2 folds. Finally, you calculate the average performance.
Is this clear now or should I elaborate more?
Hi, I was wondering if you had finished writing about the remaining parts: Algorithmic Approach, ML Algorithm Selection- Hyper-parameter Tuning, and Model Deployment. I can’t find them on the website and I am very interested in finishing reading about them!
Hi, these blog posts are long overdue. I have not finished writing them yet. I hope I will find some time to complete (some of) them soon.