Why is Data Science still hard?
Data Science and Machine Learning have evolved a lot in the past 7 years that I’ve been practically involved in the domain. ML, with the help of the newest Deep Learning methods, has made huge advancements and problems that were considered untouchable 5 years ago, have now been solved. The good performance of ML on seemingly difficult tasks, like computer vision and natural text understanding, have made it look easy – especially to the newcomers. Too easy to be honest! In this post, I want to explain why Data Science, a field encompassing a much broader area than only pure ML, is still hard and why I don’t see it being automated anytime soon.
Just a few years ago the whole world was saying that “Data Science is the sexiest job in 21st century” and now some “experts” are claiming that “Data Science will be automated by 2020”! Oh, so next year will I have to be looking for a new career? Well… not really!
Why even discuss about Data Science automation?
There are many reports supporting, for instance, that 40% of the Data Science tasks will be automated by 202X (e.g. this article from Gartner). While this could be true percentage-wise – although 40% still sounds way too high for the near future – realistically AI can only replace Data Scientists when it comes to lower-level tasks like ingesting data, visualization, model fitting, model deployment and monitoring. The hardest parts, which I’ll talk about later, are nowhere close to being solved.
This whole movement towards statements similar to the above one, has been helped by two factors. The first reason that fuels such statements are the advancements in the so-called AutoML – short for ‘automated machine learning’ – solutions, with H2O.ai and DataRobot being leading startups in this domain. The main offering of these solutions is to train models using different algorithms with different hyper-parameters, and validate their accuracy to select the best model. There have been efforts to automate feature engineering as well but most of them focus on non-linear transformations of a given feature table, which is just a small component of the feature engineering process and which still relies on manual creation of the feature table.
Another factor contributing to those beliefs is that it is now almost trivial for anyone with a decent software engineering experience to train very complex models on a given dataset, even in the absence of AutoML. This has been facilitated by the simplification of ML libraries (e.g. scikit-learn, Keras) that make ML look as easy as `model.fit(X, y)` and `model.predict(X, y)`. That’s all Data Scientists are doing every day, right? Well, this could not be farther from being truth. Using an ML API with no understanding of basic ML stuff (e.g. cross-validation, bias, variance) leads to a misleading sense of success while the actual models are useless or even dangerous in certain cases.
Is AutoML the solution?
So, are we close to automating Data Science? First things first, AutoML is not automated Data Science. These tools can help Data Scientists to be more productive but they do not – by any means – automate their work. AutoML can manage simple and repeatable tasks, but more challenging tasks are still a problem. These tools can also help non-experts, like data analysts or software engineers without formal ML knowledge, “do Machine Learning”. The number of these so-called citizen Data Scientists is expected to grow five times faster than the number of expert data scientists in 2020 and the democratization of Data Science definitely enables that. AutoML tools can help anyone create a decent baseline model if the data have been ingested, cleaned and prepared for the modeling process. However, this is a big “if” since these exact steps are the most time-consuming ones and where the Data Science expertise is still undeniably necessary.
To better understand what has been automated and what’s not, the following chart shows a high level process for all Data Science projects (taken from CRISP-DM methodology). The darker the region, the more that area has been automated.
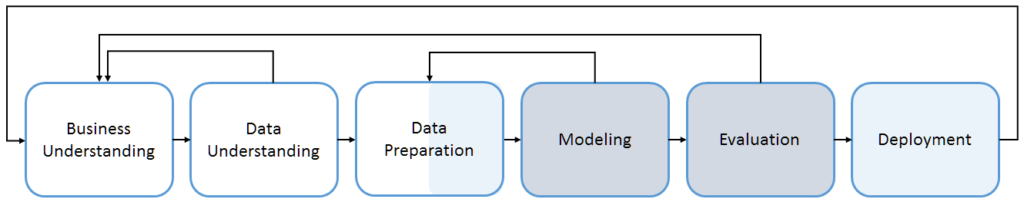
As explained previously, AutoML’s first target was the model building and evaluation phases. The standardization of ML APIs and the progress in hyper-parameter tuning has enabled such advancements. Still, there are far more things to improve even in those areas, that’s why I did not make them completely dark. From a modeling perspective, human experts are still better at finding a more performant model compared to AutoML solutions. From an evaluation perspective, this pipeline assumes that you somehow already know what to optimize for. This might be the case with toy datasets or kaggle competitions, but in real-world projects this knowledge comes from the business understanding.
Now, some platforms offer model deployment solutions that make it easy to publish a trained model behind a REST API with the click of a few buttons. While this is indeed helpful in some use cases, in general it still requires a combination of rare-to-find Data Science and Software Engineering skills to deploy ML models. The demand for ML engineers is not going to decrease anytime soon, trust me.
The ‘Data Preparation’ step is on purpose half-painted. The blue-ish part refers to some efforts towards automating feature engineering. Apart from not being a substitute for domain knowledge, these routines need a dataset in the correct format to start with. In other words, they cannot even work without a properly formatted dataset. The following chart highlights the amount of manual work that needs to be done before the feature engineering:
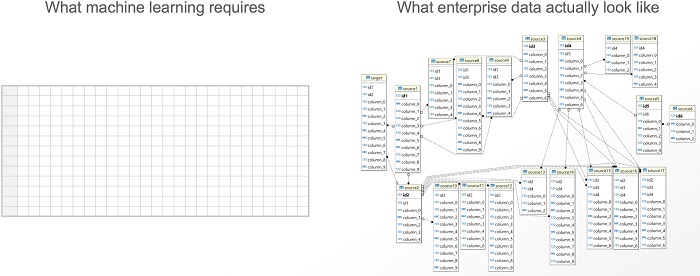
With parts of the DS process not even touched by the existing automations and when the most heavily-automated parts of the DS process are still lagging behind human experts, how can we even dare to say that DS will be automated by 202X?
What is hard in Data Science
This all brings us to the core of the problem. Data Science isn’t all about applying the latest method/algorithm to some vast amount of data. It’s not about fooling around with the coolest Deep Learning architectures and frameworks. Almost always, it’s about figuring out the right business or scientific question, translating that question into a data science problem and figuring out what kind of data could help answer that question and how you can collect them. For most data scientists, the longer they have been in this industry, the simpler their models have become.
The output of data science is not numbers, it is decisions. Data Science tries to solve business (or scientific) problems. It goes without saying that a deep business understanding is essential. You have to start with the problem definition before choosing the best way to solve it. And believe me, this is really hard to do! Many junior Data Scientists as well as some senior executives without proper ML background prefer to use the latest magical Deep Learning solution to a problem they have not even defined yet! Standard recipe for failure…
After understanding both the business context and the data you need to collect or have already collected and you have translated them into a data science problem, you can start preparing the data for the task at hand. This step refers to the white half of the ‘Data Preparation’ step described above. In the vast majority of the cases, the data will come from disparate sources – a database here, some CSV files there, a no-SQL storage system with possibly useful information and so on. The Data Scientists, or the Data Engineers, have to bring these data into a normalized form where each observation (or row) contains all the information needed for the ML model to work upon. There is no magic black box where you input any data to instantly get a perfectly working model. Don’t forget that all dirty data is dirty in its own way.
Big part of this process is also the data annotation process which can range from relatively easy (if the data contain some explicit or implicit feedback) to very hard (if you need expert human annotators go over thousands of such observations and manually label them).
I won’t go through all the evident difficulties of the somewhat-automated parts but allow me to say that proper feature engineering, modeling and model evaluation (including choosing an evaluation metric that optimizes what the business is really looking for) are both hard and important for a successful Machine Learning problem.
Apart from the above, an aspect of this difficulty involves building an intuition for what tool should be leveraged to solve a problem. This requires being aware of available algorithms and models and the trade-offs and constraints of each one. Supervised learning is a relatively straightforward domain, but what happens in other cases like unsupervised learning (e.g. anomaly detection), heavily imbalanced supervised problems or time series analysis? The existing AutoML tools are either not applicable or not that good in such cases.
Last but not least, the final decision-making lies on the human to take, especially in use cases where the decisions could have critical consequences such as in medical applications. The human judgement is still necessary and will probably remain so for many years to come. But even in simpler cases, knowing where to set a threshold or what to do when a model is not confident is up to the Data Scientist to handle.
Will Data Science be automated anytime soon?
I hope it is now clear why we are not even close to automating the whole range of activities that fall under the Data Science umbrella. It’s humans who need to do the business problem identification as machines cannot judge what organizations need and what they do not as humans would. It’s humans who have to understand the data and decide what’s possible and what’s not. It’s humans who should collect and prepare the data way before any modeling attempt begins. And in the end of the day, it’s humans who should take a decision on whether a loan should be given, whether a CT scan indicates a malignant tumor, whether a certain behavior is indeed fraudulent and so on.
I don’t see automation taking away data science work, I see it increasing the need for it. Borrowing from Randy Olson, “the purpose of AutoML is not to replace data scientists, just the same as intelligent code auto-completion tools aren’t intended to replace computer programmers”. As Jeremy Achin , CEO of DataRobot, puts it “if everyone on the planet became data scientists there still wouldn’t be enough”! While others may lose their “repeatable” jobs, more data scientists will be needed to support automated tasks and fill out higher-level positions that require knowledge of AI and Machine Learning. Innovation in automated data science drives demand for data scientists who can handle these advanced tasks.
If you are one or can become one of them, rest assured that you are not going to be replaced by a bot anytime soon! The thing is if you are one of them… you already know all that!
One thought on “Why is Data Science still hard?”
X